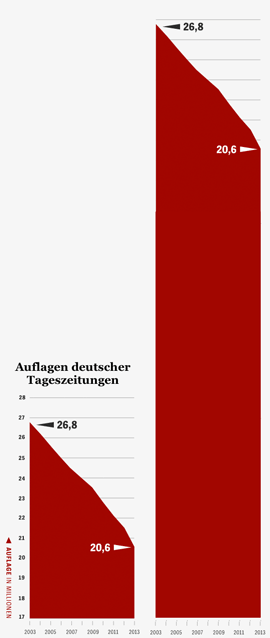
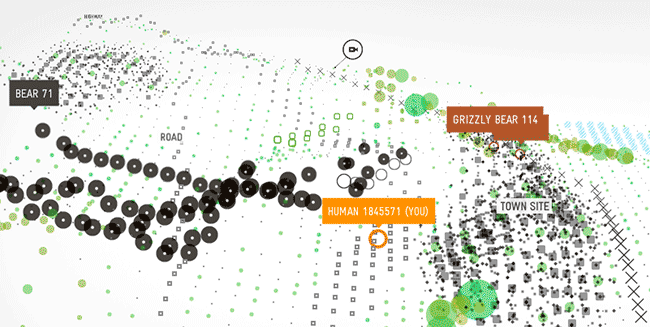
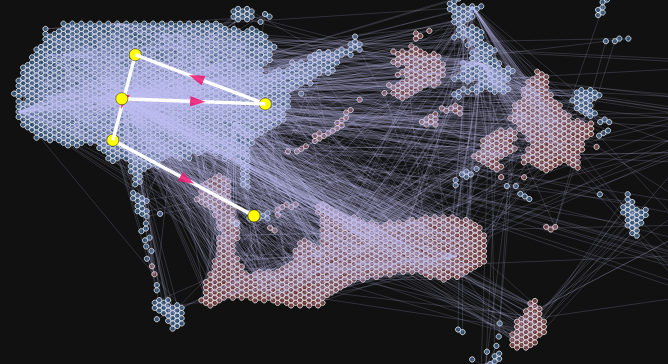
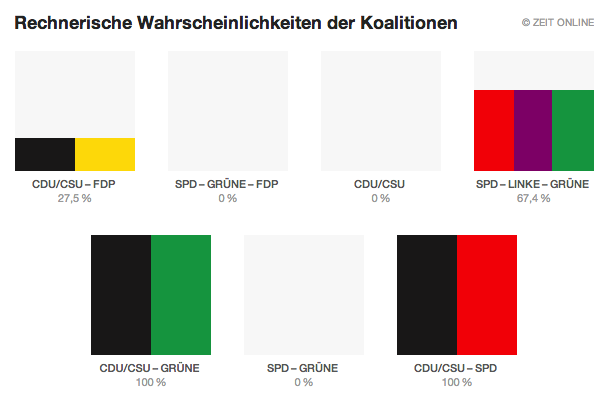
Christina Elmer @chelm, geboren 1983, arbeitet im Wissenschaftsressort von Spiegel Online und betreut als Recherche-Trainerin Workshops in Redaktionen und Ausbildungsprogrammen. Zuvor gehörte sie zum Team Investigative Recherche des Stern und arbeitete als Redakteurin für Infografiken bei der Deutschen Presse-Agentur (dpa), wo sie zuvor „dpa-RegioData“ mit aufgebaut hatte. Der Weg dorthin: Volontariat beim Westdeutschen Rundfunk (WDR), Studium der Journalistik und Biologie an der TU Dortmund, Freie Autorin für Wissenschaftsthemen.
Bezeichnest du dich selbst als Datenjournalistin? Wenn ja, wie würdest du dein berufliches Selbstverständnis beschreiben?
Ja, aus meiner Sicht passt diese Bezeichnung. Viele meiner Recherchen basieren auf Statistiken oder anderen strukturierten Datensätzen. Daraus Ansatzpunkte für Geschichten herauszukitzeln, würde ich als Kern der datenjournalistischen Arbeitsweise bezeichnen. Mein Fokus liegt dabei immer auf der Frage, ob am Ende eine relevante Story steht. Die kann sich entweder aus der Analyse ergeben oder auch darin bestehen, wichtige Datensätze überhaupt öffentlich zu machen.
Du sagst, die Recherche in Statistiken oder strukturierten Daten sei für dich der Kern datenjournalistischer Arbeit. Ist Datenjournalismus also ein anderes Wort für „Computer Assisted Reporting“ (CAR), wird er durch die Recherche definiert?
Wer datenjournalistisch arbeitet, benutzt zwangsläufig immer auch Werkzeuge und Methoden aus dem Computer Assisted Reporting. Allerdings geht der Datenjournalismus für mich darüber weit hinaus. Wenn Datenjournalisten bei ihren Recherchen dafür sorgen, dass Informationen überhaupt öffentlich werden. Wenn sie diese Daten zugänglich machen, indem sie sie ansprechend aufbereiten und auf offenen Plattformen veröffentlichen. Und wenn sich aus diesen Anwendungen neue Wege des Storytellings ergeben. Das sind alles relevante Bestandteile datenjournalistischer Arbeit, die aus meiner Sicht aber nicht in jedem Projekt zwingend eine Rolle spielen müssen.