Corona-Prognosen mit Pi-mal-Daumen-Daten
Über den möglichen Effekt der Corona-Mutante B117 auf den Pandemieverlauf in Deutschland gab die Süddeutsche Zeitung unlängst Prognosen ab. Diesen Teil des Stücks „Die unsichtbare Welle“ halte ich für Alarmismus. Wohlgemerkt geht es nicht darum, zu sagen, die Mutation B117 sei nicht ansteckender oder sie sei harmlos. Der Punkt ist: Ihr Effekt lässt sich schwer vorhersagen und die Herleitung der Szenarien der SZ steht auf wackeligen Füßen. (Die SZ recyclt die alarmistische Prognose zahlenmässig leicht entschärft in einem Beitrag (Paywall) von heute: „Die magische 50“. Der Spiegel veröffentlichte (Paywall) heute ebenfalls Modellrechnungen, die auf ähnlichen Annahmen wie die der SZ fußen.)
[Siehe Kommentar von zwei der Autoren unten.]
Um den Einwand vorwegzunehmen, dass die SZ im Text sehr wohl auf „Unsicherheiten“ hinweisen würde: Meiner Meinung nach ist es nicht Aufgabe von Journalismus, Spekulation zu betreiben. Wenn ein gewisses Maß an Unsicherheit herrscht, wenn etwas „ähnlich schwer zu kalkulieren“ ist, dann sollte man es besser einfach lassen. Prognosen sind nicht das Geschäft von Journalismus, geschweige denn die unterkomplexe Modellierung von Pandemieverläufen.
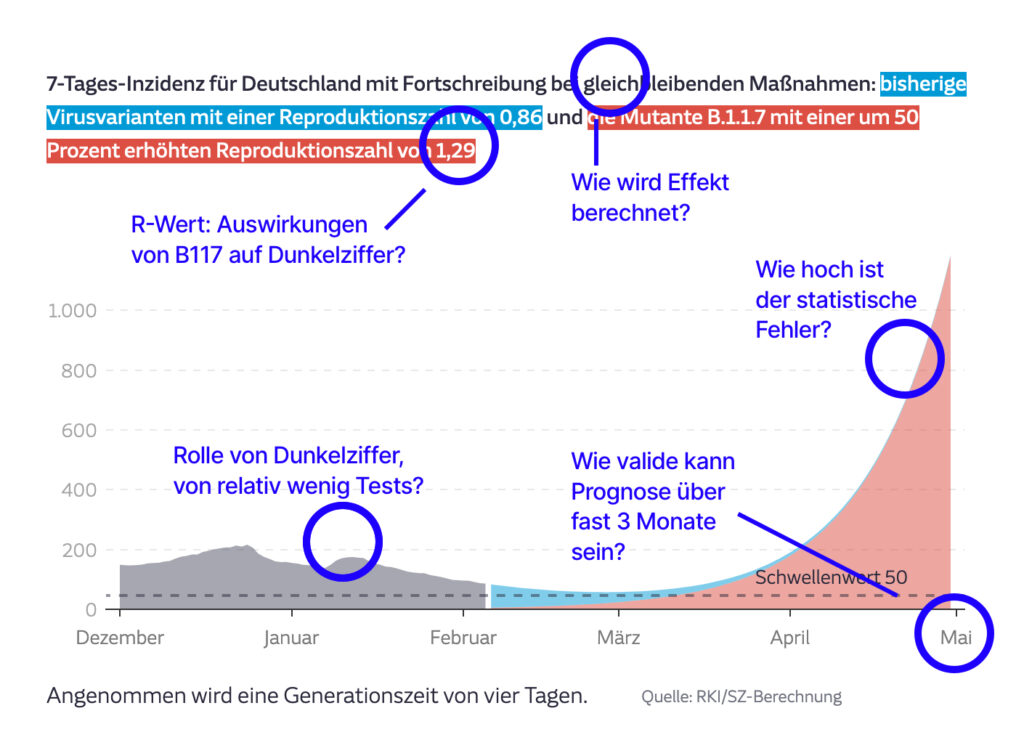
Denn so kommt es zu solch‘ Geraune: „Ohne einen verschärften Lockdown“ und ohne einen Impfeffekt, so die SZ, wäre „sogar eine Inzidenz von mehr als 1000 gegen Ende April möglich.“ Die Steilheit diese These wird dann noch in einem Diagramm präsentiert: So tritt das Problem der autoritativen Wirkung von Datenvisualisierungen ein. Die werden schnell als wahrhaftig wahrgenommen – noch mehr, wenn sie weitgehend kontextfrei auf Social Media zirkulieren. Darüber schrieb ich vor einigen Wochen – lustigerweise auch unter dem Titel „Die unsichtbare Welle“ – für den Freitag.
Gummimetrik Inzidenz
Die SZ legt ihren Prognosen den „R-Wert“ und die 7-Tagen-Inzidenz zugrunde. Beide Metriken sind hierzulande recht grobe Indikatoren für den Pandemieverlauf (siehe dazu diese Diskussion des R-Werts beim BR.) Warum sind sie grob? Weil sie beide einzig aus der Anzahl der positiven Tests abgeleitet werden: Wird weniger getestet, sinkt die Zahl der erkannten Infektionen; steigt die Zahl der Tests, steigt auch die Zahl der erkannten Infektionen.
B117-Alarmismus in der SZ weiterlesen

 Die taz hat in Kooperation mit Partnern eine Reihe „
Die taz hat in Kooperation mit Partnern eine Reihe „ Das „TV Meter“ – ein nicht realisiertes Datenjournalismusprojekt aus meiner Schublade
Das „TV Meter“ – ein nicht realisiertes Datenjournalismusprojekt aus meiner Schublade Algorithmic Accountability ist ein im Entstehen begriffenes Subgenre des Datenjournalismus. Der Ausdruck wurde durch den Journalismusforscher Nicholas Diskopoulus etabliert. Sein Bericht „
Algorithmic Accountability ist ein im Entstehen begriffenes Subgenre des Datenjournalismus. Der Ausdruck wurde durch den Journalismusforscher Nicholas Diskopoulus etabliert. Sein Bericht „