Für viele Datenjournalistinnen und -journalisten hierzulande wird der kommende Sommer wohl wenig Verschnaufpausen bieten. Das Ende der Pandemie (zumindest in Europa) ist zwar in Sicht, wenn auch nicht vollends ausgemachte Sache. Doch in den Datenteams in den Redaktionen in Deutschland dürften sich bereits viele Blicke auf die Wahlen im Herbst richten. In dem dazugehörigen Wahlkampf spielt Klimapolitik schon jetzt eine wesentliche Rolle.
Die Covid19-Pandemie bedeutete eine Zäsur für den Datenjournalismus. Markierten die Afghanistan War Logs von 2010 quasi die Geburtsstunde des data-driven-journalism, hat er es zehn Jahre später tagtäglich auf die Start- und Titelseiten geschafft. Waren zuvor Graphen und Tabellen nur im Sport und bei der Börse sowie Kartenvisualisierungen im Wetter täglich wiederkehrender Bestandteil, sind jetzt Dashboards, Graphen, Diagramme und Karten zu Infektionszahlen & Co. normal geworden. Zudem finden sich mittlerweile ellenlange, über viele Monate angewachsene und verfeinerte Datendossiers vollgepfropft mit Diagrammen auf diversen Nachrichtenwebsites.

Angesichts der erfreulichen Klickzahlen für die Datenstücke wird sich in Redaktionen sicher Gedanken darüber gemacht, was demnächst an die Stelle der Infektionszahlen treten könnte. Es liegt auf der Hand, dass Klimadaten-Dashboards ein möglicher Ersatz wären. Doch die hohe Aufmerksamkeit für die Pandemiedaten rührt daher, dass es um Fragen von Gesundheit, gar um Leben und Tod ging – des eigenen und des der eigenen Nächsten. Zudem hingen unmittelbare, spürbare Einschränkungen von der Entwicklung der Zahlen ab.
Auch wenn die Klimakrise mit jedem Einzelnen im Zusammenhang steht, ist es doch deutlich schwerer den unmittelbaren Bezug abzubilden und erfahrbar zu machen. Das ist die Crux der Klimakrisenkommunikation: Seit Jahrzehnten ist bekannt, dass der Klimawandel kommt, doch passiert ist zu wenig – auch weil die Folgen scheinbar weit in der zeitlichen Ferne liegen und die Klimawandelphänomene über den gesamten Globus scheinbar unzusammenhängend verteilt sind.
Klimadatenjournalismus weiterlesen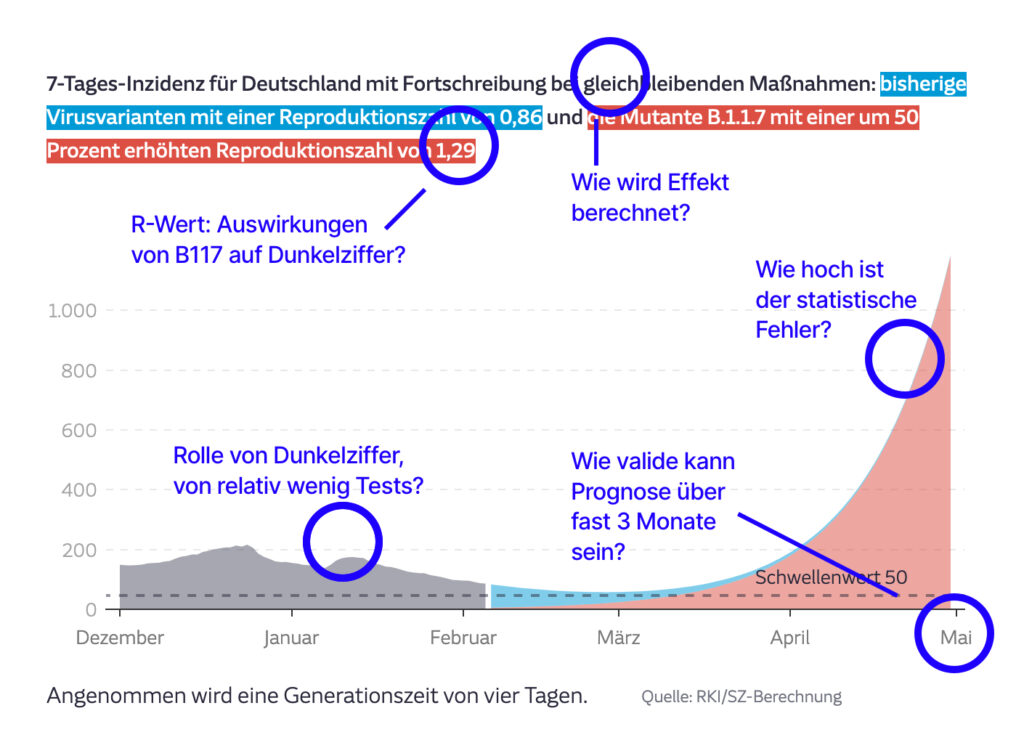
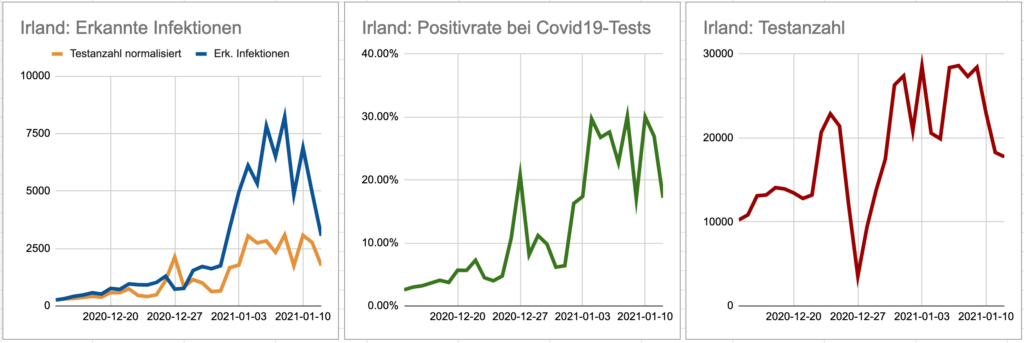


 Die taz hat in Kooperation mit Partnern eine Reihe „
Die taz hat in Kooperation mit Partnern eine Reihe „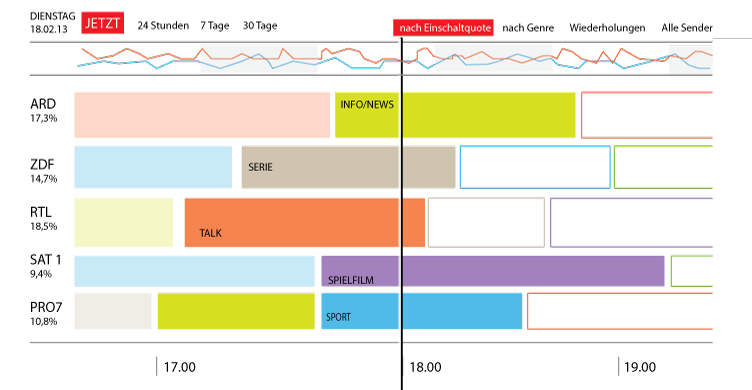 Das „TV Meter“ – ein nicht realisiertes Datenjournalismusprojekt aus meiner Schublade
Das „TV Meter“ – ein nicht realisiertes Datenjournalismusprojekt aus meiner Schublade Algorithmic Accountability ist ein im Entstehen begriffenes Subgenre des Datenjournalismus. Der Ausdruck wurde durch den Journalismusforscher Nicholas Diskopoulus etabliert. Sein Bericht „
Algorithmic Accountability ist ein im Entstehen begriffenes Subgenre des Datenjournalismus. Der Ausdruck wurde durch den Journalismusforscher Nicholas Diskopoulus etabliert. Sein Bericht „