 Die taz hat in Kooperation mit Partnern eine Reihe „Netzwerk AfD“ gestartet. Die interaktive Grafik zu der Recherche wurde mit zwei externen Entwicklern zusammen umgesetzt. Gefördert wurde das Vorhaben durch die Otto-Brenner-Stiftung. 20.000 Euro, so war es im taz Innovationsreport zu lesen, betrug das Budget.* Bereits im März 2018 hatte Zeit Online einen längeren Bericht über den rechtsradkikalen Hintergrund diverser Mitarbeiter der AfD-Bundestagsfraktion gebracht; das taz Projekt ist also kein „Scoop“. Dennoch ist die systemtatische Recherche der taz & Co hilfreich und wichtig. Bislang ist die Datenbank, die dabei entstanden ist, im Sinne von Open Data nicht zugänglich. Die Grafik weist aus meiner Sicht einige konzeptionelle Schwächen auf:
Die taz hat in Kooperation mit Partnern eine Reihe „Netzwerk AfD“ gestartet. Die interaktive Grafik zu der Recherche wurde mit zwei externen Entwicklern zusammen umgesetzt. Gefördert wurde das Vorhaben durch die Otto-Brenner-Stiftung. 20.000 Euro, so war es im taz Innovationsreport zu lesen, betrug das Budget.* Bereits im März 2018 hatte Zeit Online einen längeren Bericht über den rechtsradkikalen Hintergrund diverser Mitarbeiter der AfD-Bundestagsfraktion gebracht; das taz Projekt ist also kein „Scoop“. Dennoch ist die systemtatische Recherche der taz & Co hilfreich und wichtig. Bislang ist die Datenbank, die dabei entstanden ist, im Sinne von Open Data nicht zugänglich. Die Grafik weist aus meiner Sicht einige konzeptionelle Schwächen auf:
Autor: Lorenz Matzat
Die Vermessung des TV-Programms
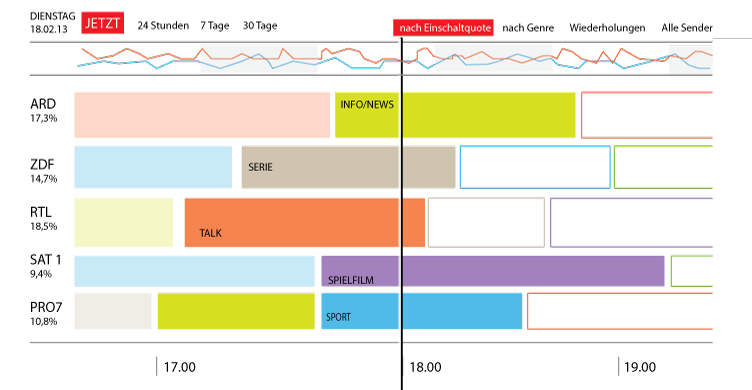 Das „TV Meter“ – ein nicht realisiertes Datenjournalismusprojekt aus meiner Schublade
Das „TV Meter“ – ein nicht realisiertes Datenjournalismusprojekt aus meiner Schublade
Gefühlt besteht das Angebot des öffentlich-rechtlichen Fernsehens aus Quizshows, Krimis, Sport und Schlagersendungen plus etwas Nachrichten, Politiksendungen sowie Talkshows.
Derlei Gefühle ließe sich recht einfach mit Zahlen unterfüttern: Das Fernsehprogramm kommt seit eh und je in Tabellenform daher. Vor allem die ARD macht es einfach, ihr Programm auszulesen:
http://programm.ard.de/TV/Programm/Sender?datum=09.01.2018&hour=0&sender=28106
Unter dieser URL findet sich das Programm der ARD für einen Tag. Die Struktur der URL macht deutlich, dass es simpel sein dürfte, zurückliegende Tage bzw. zukünftige aufzurufen. Offenbar scheint das komplette Programm über den Parameter „datum“ seit 2011 und 40 Tage im Voraus abrufbar zu sein.
Auch deutet der Parameter „sender“ in der URL an, dass sich andere Sender abrufen lassen: Neben allen 3. Programmen finden sich auch die Programme von Phoenix, arte, Kika, One, ARD-alpha und tagesschau24.
Algorithmic Accountability: Der nächste Schritt für den Datenjournalismus
 Algorithmic Accountability ist ein im Entstehen begriffenes Subgenre des Datenjournalismus. Der Ausdruck wurde durch den Journalismusforscher Nicholas Diskopoulus etabliert. Sein Bericht „Algorithmic Accountability Reporting: On the Investigation of Black Boxes“ erschien Anfang 2014. Er skizziert eine neue Aufgabe für Journalisten: Sie sollten Softwaresysteme als Gegenstände der Berichterstattung verstehen. Dabei kann reine Transparenz nicht das Ziel sein – meistens hilft es nicht, nur auf den Programmiercode der Software so genannter Künstlicher Intelligenz (AI) oder Machine Learning zu schauen. Ohne die Datensätze, mit denen diese Systeme trainiert werden, kann ihre Funktionsweise nicht verstanden werden. Deshalb setzt Algorithmic Accountability auf Nachvollziehbarkeit.
Algorithmic Accountability ist ein im Entstehen begriffenes Subgenre des Datenjournalismus. Der Ausdruck wurde durch den Journalismusforscher Nicholas Diskopoulus etabliert. Sein Bericht „Algorithmic Accountability Reporting: On the Investigation of Black Boxes“ erschien Anfang 2014. Er skizziert eine neue Aufgabe für Journalisten: Sie sollten Softwaresysteme als Gegenstände der Berichterstattung verstehen. Dabei kann reine Transparenz nicht das Ziel sein – meistens hilft es nicht, nur auf den Programmiercode der Software so genannter Künstlicher Intelligenz (AI) oder Machine Learning zu schauen. Ohne die Datensätze, mit denen diese Systeme trainiert werden, kann ihre Funktionsweise nicht verstanden werden. Deshalb setzt Algorithmic Accountability auf Nachvollziehbarkeit.
Im Unterschied zu „traditionellem“ Datenjournalismus, der mit manuell oder automatisiert gesammelten Datensätzen operiert, kümmert sich Algorithmic Accountability darum, wie Daten verarbeitet und/oder generiert werden. Ein gutes Beispiel ist die Arbeit von Pro Publica in der Serie „Machine Bias“ aus dem Jahr 2016. Unter anderen untersuchte die Redaktion eine im Strafprozesserfahren der USA weitverbreitetete Software, die bestimmt, ob ein Verurteilter Bewährung erhalten sollte. Sie fand heraus, dass diese Software Rassismus reproduziert. Die verantwortliche private Softwarefirma war nicht bereit, die Funktionsweise der Software im Detail offenzulegen. Pro Publica gelang es durch eine Informationsfreiheitsanfrage, Daten zu Verurteilen zu erhalten und betrieb auf dieser Grundlage eine Art „Reverse Engineering“ (Nachkonstruktion) des Softwaresystems.
Algorithmic Accountability ist der nächste logische Schritt in einer Welt des automatisierten Entscheidens (Automated Decision Making – ADM): Demokratische Gesellschaften, die vermehrt durch und mit Software regiert werden, müssen in der Lage sein, solche „Maschinen“ zu verstehen und kontrollieren.
—
Deutsche Fassung meines englischsprachigen Beitrags im Data-Driven Advent Calender von Journocode. Ein ausführlicher Text von mir zu Algorithmic Accountability findet sich bei der Bayerischen Landesmedienanstalt: „Rechenschaft für Rechenverfahren“
Wie es dem Gesichtserkennungs-Stück des Morgenpost-Interaktivteam misslingt, großartig zu sein

Die eigentlich gut gemachte Auseinandersetzung mit Gesichterkennungs-Algorithmen krankt an einer mangelnden Beschäftigung mit dem Datenschutz des eingesetzten Microsoft-Dienstes (UPDATE: Mittlerweile wird deutlich auf die Datenübermittlung hingewiesen).
Es könnte wegweisend für ein ein neues Genre des Datenjournalismus sein: Mit einem Stück zur Gesichtserkennung greift das Interaktiv-Team den Hype um „Künstliche Intelligenz“ auf und macht sie praktisch erfahrbar. Dabei kommt eben auch die lokale Komponente des Kameraüberwachung mit Gesichterkennung der Bundespolizei am Bahnhof Berlin Südkreuz zum tragen, die in der Hauptstadt für einige Debatte sorgt.
Die Präsentation, bei der rund 80 Mitglieder der Morgenpost-Redaktion sich mit ihrem Gesicht (und Alter) für einen Selbstversuch hergeben, ist schlicht eine gute Idee: Sie erlaubt anhand der Portraits zu erahnen, warum der verwendete Gesichterkennungs-Algorithmus möglicherweise Probleme hatte, das Alter der Person richtig einzuschätzen.
Der Höhepunkt des Beitrags ist aber die Möglichkeit, über die eigene Webcam/Smartphone-Kamera sein eigenes Gesicht zu übermitteln und eine Alterseinschätzung zu erhalten. Damit wird der Ansatz, dass für die Wirkung eines datenjournalistischen Werks die Ermöglichung des persönlichen Bezugs wichtig ist, gelungen eingelöst.
Leider ist es diese eigentlich tolle Idee, an der das Stück scheitert: Die Morgenpost setzt einen Dienst von Microsoft ein. Das ist an sich nicht verwerflich. Doch klärt die Redaktion an dieser Stelle kaum auf, was eigentlich mit den Daten des „Daten-Selfies“ geschieht, die dort über die Kamera erfasst werden. Zwar wird gleich unterhalb des Aufnahmeknopfs auf die Datenschutzerklärung des Microsoft-Dienstes verwiesen. Doch die scheint nicht mal die Redaktion gänzlich verstanden zu haben. Wie es dem Gesichtserkennungs-Stück des Morgenpost-Interaktivteam misslingt, großartig zu sein weiterlesen
Ein Genre wird erwachsen
Dieser Beitrag erschien zuerst in „M – Menschen Machen Medien“ (dju/ver.di) im März 2017.
Es ist sieben Jahre her, dass M erstmalig Datenjournalismus als Titelthema brachte. Unter der Überschrift „Spannende Recherche im Netz” wurde von damals noch exotisch klingenden Begriffen wie „Open Data” und „Datenbank-Journalismus” berichtet. Seither ist aus einem Nischenthema ein Genre erwachsen.
Indidikator für die Entwicklung dieses Genres ist etwa, dass das Reporterforum seit zwei Jahren in seinem Reporterpreis Auszeichnungen für Datenjournalismus vergibt. Oder die langsam aber stetig steigende Zahl der Stellenanzeigen, wie sie unlängst die Süddeutsche Zeitung veröffentlichte: Der mittlerweile vierte Datenjournalist für die Redaktion wird gesucht.
Die Datenjournalisten der SZ hatten ihren Anteil an den „Panama Papers”, der Recherche der SZ und anderer Redaktionen über die Steueroase in Mittelamerika 2016. An ihrer Herangehensweise lässt sich gut zeigen: Die eine Definition von Datenjournalismus gibt es nicht. Oder besser gesagt, dass Selbstverständnis darüber, was Datenjournalismus genau ist, variiert. Die Panama Papers etwa könnte man auch schlicht als „Computer Assisted Reporting” (CAR, computergestützte Recherche) verstehen – eine jahrzehntealte Methode im investigativen Bereich. Datenvisualisierungen spielten bei der Veröffentlichung des preisgekrönten Werks über die Steueroase keine zentrale Rolle. Doch ist es dieser Faktor, den manche als wesentlichen Aspekt für Datenjournalismus oder data-driven journalism (#ddj) verstehen: Die zugrundeliegenden Daten spielen nicht nur in der Recherche, sondern auch in dem veröffentlichen Werk in Form visueller Elemente eine wichtige Rolle. So oder so, einig dürften sich alle sein: Datensätze sind beim Datenjournalismus wesentlich. Mittels manueller Auswertung, etwa per Tabellen-Kalkulationsprogrammen wie Excel, oder halb- oder ganz automatischen Verfahren durch Softwarebibliotheken oder selbstgeschriebenem Programmcode werden die Datensätze ausgewertet und nach Auffälligkeiten abgeklopft. Als Faustregel bei einem datenjournalistischen Stück kann gelten: 70 Prozent der Arbeit steckt in der Datenbeschaffung, -säuberung und -validierung. Bevor die Daten überhaupt veröffentlichungsreif sind – in welcher Form auch immer – liegt viel Arbeit hinter den Datenredakteuren. Das fängt an beim „Befreien” der Daten aus Schriftstücken oder pdf-Dateien inklusive Lesefehlern bei der Umwandlung, reicht über die Vereinheitlichung von Formaten bis hin zu zahllosen weiteren Fallstricken, die sich während des Prozesses auftun. Sprich: Wer sich mit Datenjournalismus befasst, sollte eine hohe Frustationsschwelle und eine gewisse Affinität für Statistik mitbringen.
Die Belohnung für hartnäckiges Graben in Datenbergen sind Erkenntnisse und Perspektiven auf Sachverhalte, die bei klassischen Recherchemethoden verborgen blieben. Und diese lassen sich pointiert an die Leser_innen dank einer mittlerweile erklecklichen Anzahl an Visualisierungmethoden und -formaten unmittelbar weitergeben.
Automatisier' Dich, Lokaljournalismus
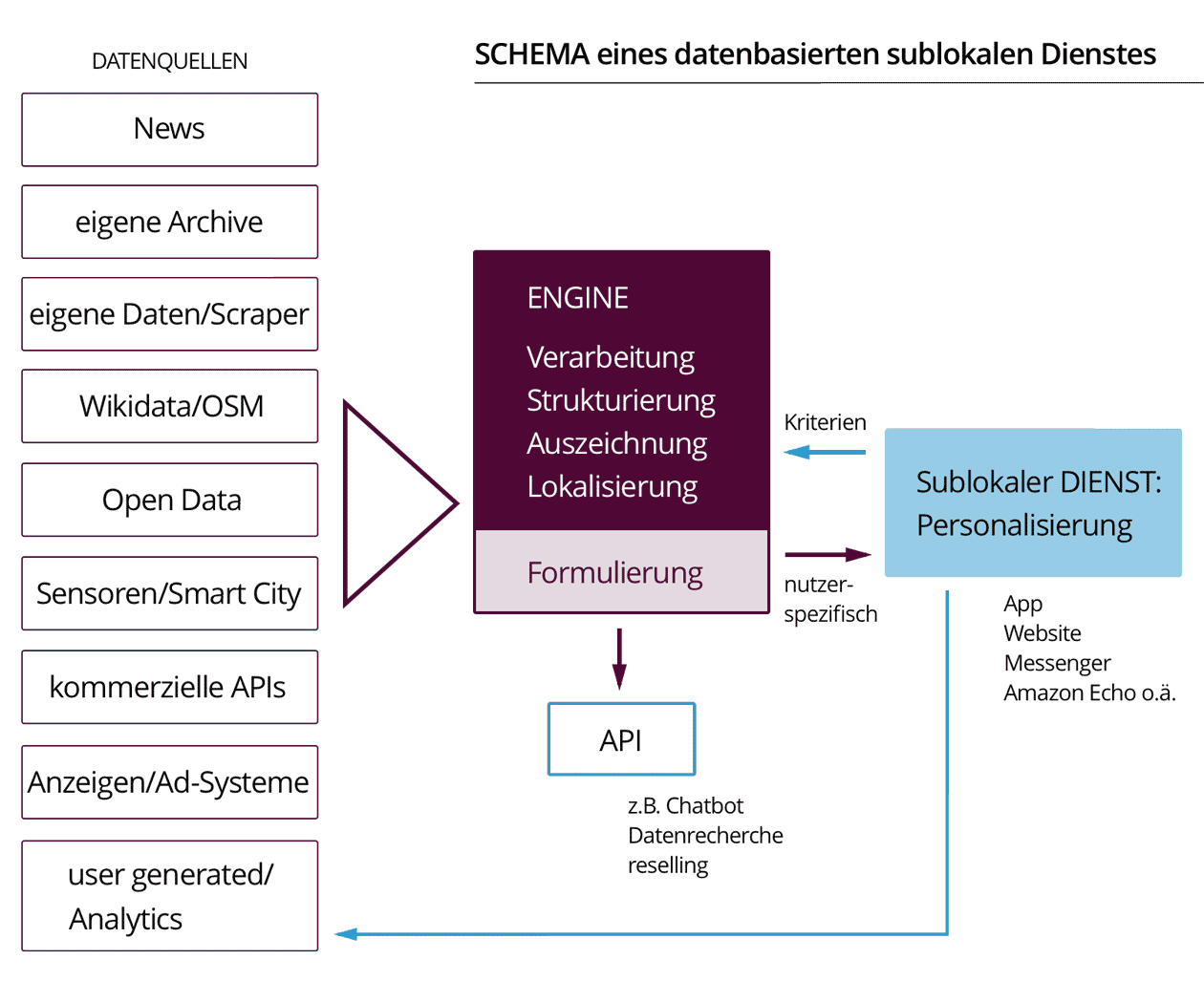
Die Stärke des Lokaljournalismus lag immer auch in einer groben ortsbasierten Personalisierung. Im Digitalen nutzt er die vielfältigen Möglichkeiten dafür kaum. Das liegt wesentlich am Print-Paradigma, das sich in den Content Managment Systemen (CMS) manifestiert und Weiterentwicklung verhindert. Stattdessen braucht es Herangehensweisen, die kleinteilig Alltagsinformationen in einzelne Datenpunkte zerlegt und abrufbar macht.
Manchmal träume ich davon, es gäbe zeitgemäßen Lokaljournalismus. Als digitalen Service, der mir morgens oder ad hoc punktgenau wesentliche Informationen für den Alltag bezüglich meines Wohn- und Arbeitsorts mitteilt. Der mich über die Verkehrssituation (S-Bahnausfall in der ganzen Stadt), Politik (Hotelneubau in deiner Nachbarstraße beschlossen), Kultur (Theaterstück X läuft kommende Woche zum ersten Mal), Infrastruktur (Sperrung des Schwimmbads wg. Renovierung), Angebote (Supermarkt an der Ecke: 10% auf alles), Bildung (wieder Kitaplätze frei), Nachbarschaft (wer hilft mit bei Renovierung des Grillplatzes), Sport (die B-Jugend hat 3:5 verloren), Alltag (morgen ist Sperrmüll) usw. usf. informiert. Gerne darf dieses Angebot auch „lernen“, was mich interessiert und mich auf Hintergrundstücke sowie Reportagen mit weiterem lokalen Bezug hinweisen.
Es ist schwer verständlich, warum Lokalzeitungen immer noch nicht hyperlokale oder sublokale Angebote dieser Art anbieten: Ein personalisierter Bericht – egal ob per Mail, App, Website, Messenger, Spracherzeugung (z.B. Amazon Echo) übermittelt. Die Daten dafür sind vorhanden, mehr und mehr davon. Aus ihren Strömen lassen sich kurze und knappe Informationshappen straßen- und interessengenau automatisch generieren. Es wird wahrlich keine Raketentechnologie mehr dafür benötigt, um klein damit anzufangen.
Die unterschätzte Ressource: Wie sich die OpenStreetMap für Journalismus nutzen lässt
Nach einem Überblick über die reichhaltige Datenquelle für geographische Informationen werden Nutzungsszenarien skizziert und einige Tools sowie Anwendungen vorgestellt. Schließlich wird ein Karteneditor präsentiert, an dem der Autor derzeit arbeitet.
Wie sieht eine Karte aus, die nicht für Navi/E-Kommerz gezeichnet wird, sondern für Journalismus?
— Guenter Hack (@guenterhack) 16. Januar 2017
Eine Antwort auf diese Frage lautet: Die Basis dafür kann nur die OpenStreetMap sein. Es ist eine der faszinierendsten offenen Datenquellen, die sich im Netz finden lässt. Die OpenStreetMap, 2006 gestartet, ist nach der Wikipedia das wohl größte gemeinschaftliche Werk, das das Netz hervorgebracht hat. In derzeit knapp 740 GB Rohdaten (XML äquivalent) liegt wahres Open Data vor – genauso frei für die kommerzielle Nachnutzung wie für gemeinnützige und private Zwecke (OpenDatabaseLicense, ODbL). Es gibt diverse daran angeschlossene Projekte, die Schwerpunkte etwa auf Fahrradfahrer, ÖPNV oder die Nutzung auf See legen.
Wikipedia für Geoinformation
Wie gelangen Informationen in die OpenStreetMap (OSM)? Jeder kann sich wie bei der Wikipedia einen Account bei der OSM anlegen und Daten beitragen sowie ändern. Neben automatisierten Importen von offenen Daten (zum Beispiel die Hausnummern Berlins) lassen sich manuelle Änderungen vornehmen. Oder Aufzeichnungen aus GPS-Geräten können importieren und die so gesammelten Punkte und Linien entsprechend markiert werden. Im Wiki der OSM ist die komplexe Taxonomie des Projekts nachzuvollziehen, die sich in ständiger Weiterentwicklung und Verbesserung durch tausende Freiwillige befindet. Die OpenStreetMap ist international über eine Stiftung mit Sitz in UK organisiert. Die „Wochennotizen“ des deutschsprachigen OSMblog vermitteln einen guten Eindruck der vielfältigen Aktivitäten rund um OSM. Und bei learnosm.org findet sich in diversen Sprachen eine ausführliche Einführung für die Mitarbeit an der freien Weltkarte.
Alle Änderungen der OSM lassen sich nachvollziehen (sogar live). In kurzer Zeit, üblicherweise nach einigen Minuten, sind die Änderungen auf der zentralen OpenStreetMap-Karte openstreetmap.org zu sehen. Die Datenbank, aus der sich jeder bedienen darf, die „planet.osm“ erfährt einmal pro Woche ein Update.
Es hilft sich zu verdeutlichen, dass eine Kartendarstellung eine Datenvisualisierung ist. Doch mit Geodaten lässt sich selbstredend einiges mehr anstellen als sie nur zu visualisieren: Das fängst damit an, Streckenführung für Navigationsgeräte zu errechnen (Routing) oder Flächenberechnung für statistische Zwecke vorzunehmen (per Geoinformationssystem, GIS). Einen eigener Artikel wert wäre das Potential, das derzeit durch das Wikidata-Projekt entsteht: Es verknüpft die Inhalte der OSM mit der Wikimedia (Wikipedia, Wikivoyage usw.) zu „Linked Data“.
Im journalistischen Kontext dürfte dem Kartenmaterial auf OSM-Basis derzeit allerdings am meisten Bedeutung zukommen. Das folgende Beispiel zeigt Karten von Google und OSM (per Griff in der Mitte lässt sich der Slider nach rechts und links bewegen). Zu sehen ist die Position des so genannten Jungles im französischen Calais, der bis vergangenen Herbst immer wieder in den Nachrichten auftauchte: Über einige Jahre hinweg hatten sich in einer improvisierten Siedlung zeitweise tausende Geflüchtete aufgehalten, um über den nahen Eingang des Eisenbahntunnels nach Großbritannien eben dorthin zu gelangen.
Die unterschätzte Ressource: Wie sich die OpenStreetMap für Journalismus nutzen lässt weiterlesen
Buch für Einsteiger: Datenjournalismus – Methode einer digitalen Welt
 Ab kommenden Montag, den 11. Juli 2016, ist mein Buch „Datenjournalismus – Methode einer digitalen Welt“ erhältlich. Die UVK Verlagsgesellschaft hatte mich vergangenes Jahr gefragt, ob ich einen Einführungsband schreiben möchte. Das mochte ich. Die Zusammenarbeit mit dem Verlag, konkret mit Frau Sonja Rothländer, hat sich als angenehm und konstruktiv erwiesen. Vielen Dank dafür!
Ab kommenden Montag, den 11. Juli 2016, ist mein Buch „Datenjournalismus – Methode einer digitalen Welt“ erhältlich. Die UVK Verlagsgesellschaft hatte mich vergangenes Jahr gefragt, ob ich einen Einführungsband schreiben möchte. Das mochte ich. Die Zusammenarbeit mit dem Verlag, konkret mit Frau Sonja Rothländer, hat sich als angenehm und konstruktiv erwiesen. Vielen Dank dafür!
Es ist ein knappes Buch geworden. Wie gesagt, es richtet sich an Einsteiger und soll eine erste Orientierung bieten. Wer einen Blick in das Buch werfen mag, findet einen Auszug auf der Website des Verlags – unterhalb des Abbilds des Covers muss dafür auf den Button „Buch öffnen“ geklickt werden.
Die Kosten für das E-Book betragen 15, für das gedruckte Buch 18 Euro.
Hier folgt jetzt das Ankündigungstext und darunter wird das Inhaltsverzeichnis aufgelistet. Falls jemand das Buch lesen sollte, freue ich mich über Kritik, Anregungen und generell Feedback.
Rezensionen:
Menschen Machen Medien – Link
„Buchtipp: „Datenjournalismus ist gekommen um zu bleiben“
Fachjournalist – Link
„Buchrezension von “Datenjournalismus”: Das Datendickicht als Geschichte“
Buch für Einsteiger: Datenjournalismus – Methode einer digitalen Welt weiterlesen
Data Journalism Awards 2016 & Unconference

Am 14. April (die Frist wurde verlängert) In zehn Tagen, am 10. April 2016, endet die Einreichungsfrist für die Data Journalism Awards 2016. Eingereicht werden können Werke, die zwischen dem 10. April 2015 und 4. April 2016 erschienen sind. Die Einreichung muss auf Englisch geschehen; dies bedeutet für deutschsprachige Datenjournalismusstücke, dass Übersetzungen angefertigt werden müssen.
 Es werden in zwölf Kategorien Preise von jeweils 1000 Euro vergeben; verliehen werden diese in Wien auf dem diesjährigen „Summit“ des Global Editors Networks, das die Awards zum fünften Mal ausrichtet. Termin der Preisverleihung ist der 16. Juni 2016.
Es werden in zwölf Kategorien Preise von jeweils 1000 Euro vergeben; verliehen werden diese in Wien auf dem diesjährigen „Summit“ des Global Editors Networks, das die Awards zum fünften Mal ausrichtet. Termin der Preisverleihung ist der 16. Juni 2016.
Zuvor wird die Shortlist der Awards am 10. Mai auf der „Data Journalism Unconference“ bekannt gegeben. Es gibt 80 Plätze auf die sich beworben werden kann. Die Veranstaltung in New York selbst ist kostenfrei; Reisekosten müssen allerdings selbst getragen werden.
–
datenjournalist.de ist Medienpartner der Data Journalism Awards 2016
Die betretbare Infografik
Wie wir Virtual Reality im Lokaljournalismus einsetzen wollen
Seit Ende vergangenen Jahres arbeiten wir an einem Virtual Reality-Projekt zum geplanten Autobahnausbau in Berlin. Wir denken, VR ist ein großartiges Medium für die Auseinandersetzung mit städtebaulichen Vorhaben. Denn es lässt eine Situationen weit vor der eigentlichen Realisierung räumlich erfahrbar machen. Insofern sollte man VR nicht nur als „Empathie-Maschine“ verstehen, sondern eben auch als Zeit- und Raummaschine.
Mit unserem Vorhaben „A100 VR“ wollen wir zeigen, wie der 17. Bauabschnitt der Stadtautobahn ausschauen könnte. Wir setzen dafür ein 3D-Stadtmodell der deutschen Hauptstadt ein und kombinieren 360-Grad Fotos mit computergenerierten Bildern. Es geht also nicht um einen 360 Grad-Film, sondern wir realisieren ein non-lineares interaktives Stück auf Basis von 3D-Grafik.
Das besondere an besagtem Bauabschnitt ist, dass er durch einen dicht besiedelten Teil von Berlin führen soll; knapp ein Kilometer davon als doppelstöckiger Tunnel, der in einer recht engen Wohnstraße wohl von oben im Boden versenkt werden soll. Zwar ist der Baubeginn nicht vor 2022 zu erwarten (wenn überhaupt, denn er ist wie der Autobahnausbau zuvor umstritten). Doch dürfte eine endgültige Entscheidung über seinen Bau deutlich früher fallen.